7 Language
MARC: 041,a
7.1 Description
The polish_languages function is designed to standardize and harmonize language information in a dataset. The process starts by isolating unique language entries, ensuring that each distinct combination of languages is processed only once, which improves efficiency and avoids redundant computations. A MARC reference list of recognized language abbreviations and names is then used to map language codes to their standardized forms. Each language entry is analyzed to identify multiple languages and to detect any unrecognized terms.
The entries are standardized by converting them to their recognized forms while eliminating duplicates and filtering out unrecognized languages. Empty cells in the dataset are marked as NA to indicate missing information. Once standardized, all valid languages are aggregated to create a structured data frame. This data frame includes the total number of languages in each entry, a flag (TRUE/FALSE) indicating whether the entry contains multiple languages (including those that are originally coded as mul = Multiple language), the cleaned and harmonized list of languages, and the primary language, which is defined as the first listed language in each entry. The result is a cleaned and standardized dataset that facilitates accurate analysis of multilingual data.
Additionally, an error list is generated, consisting of unrecognized language information and the corresponding IDs. This error list helps librarians identify mistakes in the original data and provides context to either correct the errors or explain why certain entries were discarded by the function.
7.2 Field 041,a
7.2.1 Complete Dataset Overview
Unique languages: 190
1173745 single-language entries (93.41%)
82803 multilingual entries , accounting for 6.59% of the total. This includes entries explicitly coded as “mul” (Multiple languages) as well as those with more than one language listed for a single book.
There are 297 single-language entries marked as only “Undetermined”, coded as “und”, accounting for (0.02%) of the total.
There are 61515 missing values in the dataset,accounting for (4.67%) of the total.
Unrecognized languages provides details of languages that were discarded, in total: 18. Additionally, the Error list contains ID numbers of entries associated with these discarded languages, intended for librarian review.
Conversions from raw to preprocessed language entries
Download language harmonized dataset
| Language | Entries (n) | Fraction (%) |
|---|---|---|
| Finnish | 842715 | 63.9 |
| English | 145346 | 11 |
| Swedish | 134191 | 10.2 |
| Finnish;Swedish | 28305 | 2.1 |
| German | 14883 | 1.1 |
| Latin | 14155 | 1.1 |
| Finnish;English | 12728 | 1 |
| Finnish;Swedish;English | 7376 | 0.6 |
| Russian | 5699 | 0.4 |
| Multiple languages | 5028 | 0.4 |
7.2.2 Subset Analysis: 1809-1917
Unique languages (1809-1917): 55
Unique primary languages (1809-1917): 40
67393 single-language entries (94.53%)
3903 multilingual entries , accounting for 5.47% of the total. This includes entries explicitly coded as “mul” (Multiple languages) as well as those with more than one language listed for a single book.
There are 15 entries marked as “Undetermined”.
There are 1330 missing values in the dataset,accounting for (1.83%) of the total.
7.2.3 Top languages for 1809-1917
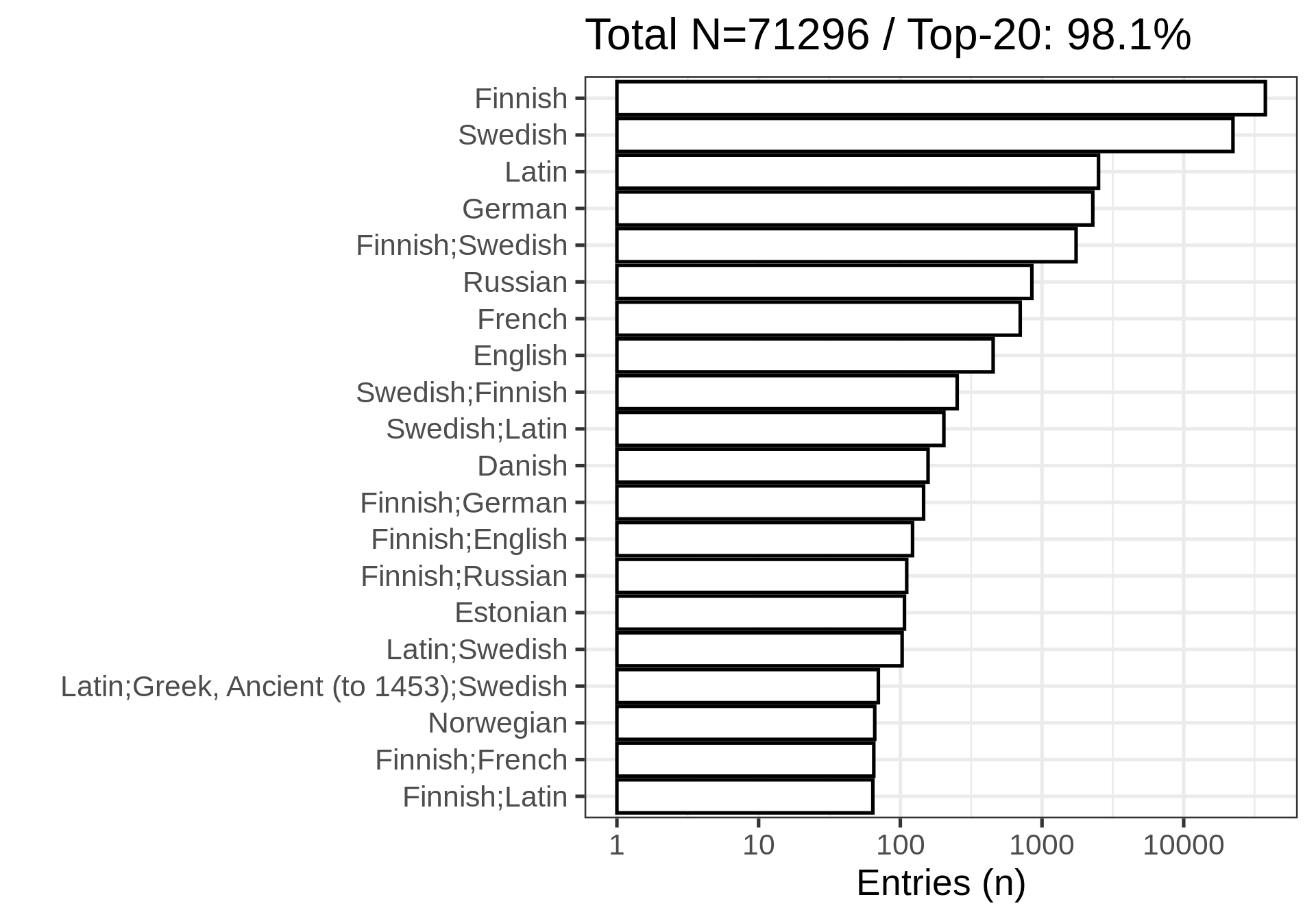
Number of titles assigned with each language (top-10). For a complete list, see accepted languages (1809-1917).
| Language | Entries (n) | Fraction (%) |
|---|---|---|
| Finnish | 37707 | 51.9 |
| Swedish | 22270 | 30.7 |
| Latin | 2506 | 3.5 |
| German | 2283 | 3.1 |
| Finnish;Swedish | 1740 | 2.4 |
| Russian | 848 | 1.2 |
| French | 702 | 1 |
| English | 452 | 0.6 |
| Swedish;Finnish | 252 | 0.3 |
| Swedish;Latin | 203 | 0.3 |
Title count per language (including multi-language documents; note the log10 scale):
7.3 Field 008
MARC field 008 contains a fixed-position language code for the language of the item. In this workflow, the language information extracted from field 008 is harmonized into the same language categories used for MARC 041,a. Both 008 and 041,a describe the language of the publication itself, not the original language of a translated work. Original-language information for translations is reported separately under 041,h.
Field 008 usually provides one coded language value per record and can therefore be treated as a primary language indicator. In contrast, 041,a may contain more detailed or repeated language information, especially for multilingual publications. The 008-based language harmonization is therefore useful as a compact, record-level language summary.
7.3.1 Complete Dataset Overview
Unique languages: 186
1307287 single-language entries (99.21%)
10370 multilingual entries , accounting for 0.79% of the total. This includes entries explicitly coded as “mul” (Multiple languages) as well as those with more than one language listed for a single book.
There are 401 single-language entries marked as only “Undetermined”, coded as “und”, accounting for (0.03%) of the total.
There are 406 missing values in the dataset,accounting for (0.03%) of the total.
Unrecognized languages provides details of languages that were discarded, in total: 1223. Additionally, the Error list contains ID numbers of entries associated with these discarded languages, intended for librarian review.
Conversions from raw to preprocessed language entries
| Language | Entries (n) | Fraction (%) |
|---|---|---|
| Finnish | 937654 | 71.1 |
| English | 154704 | 11.7 |
| Swedish | 147576 | 11.2 |
| Latin | 17692 | 1.3 |
| German | 16913 | 1.3 |
| Multiple languages | 8750 | 0.7 |
| Russian | 6580 | 0.5 |
| Unrecognized | 5819 | 0.4 |
| French | 4886 | 0.4 |
| Danish | 1796 | 0.1 |
7.3.2 Subset Analysis: 1809-1917
Unique languages (1809-1917): 42
Unique primary languages (1809-1917): 40
72319 single-language entries (99.58%)
307 multilingual entries , accounting for 0.42% of the total. This includes entries explicitly coded as “mul” (Multiple languages) as well as those with more than one language listed for a single book.
There are 17 entries marked as “Undetermined”.
There are 0 missing values in the dataset,accounting for (0%) of the total.
7.3.3 Top languages for 1809-1917
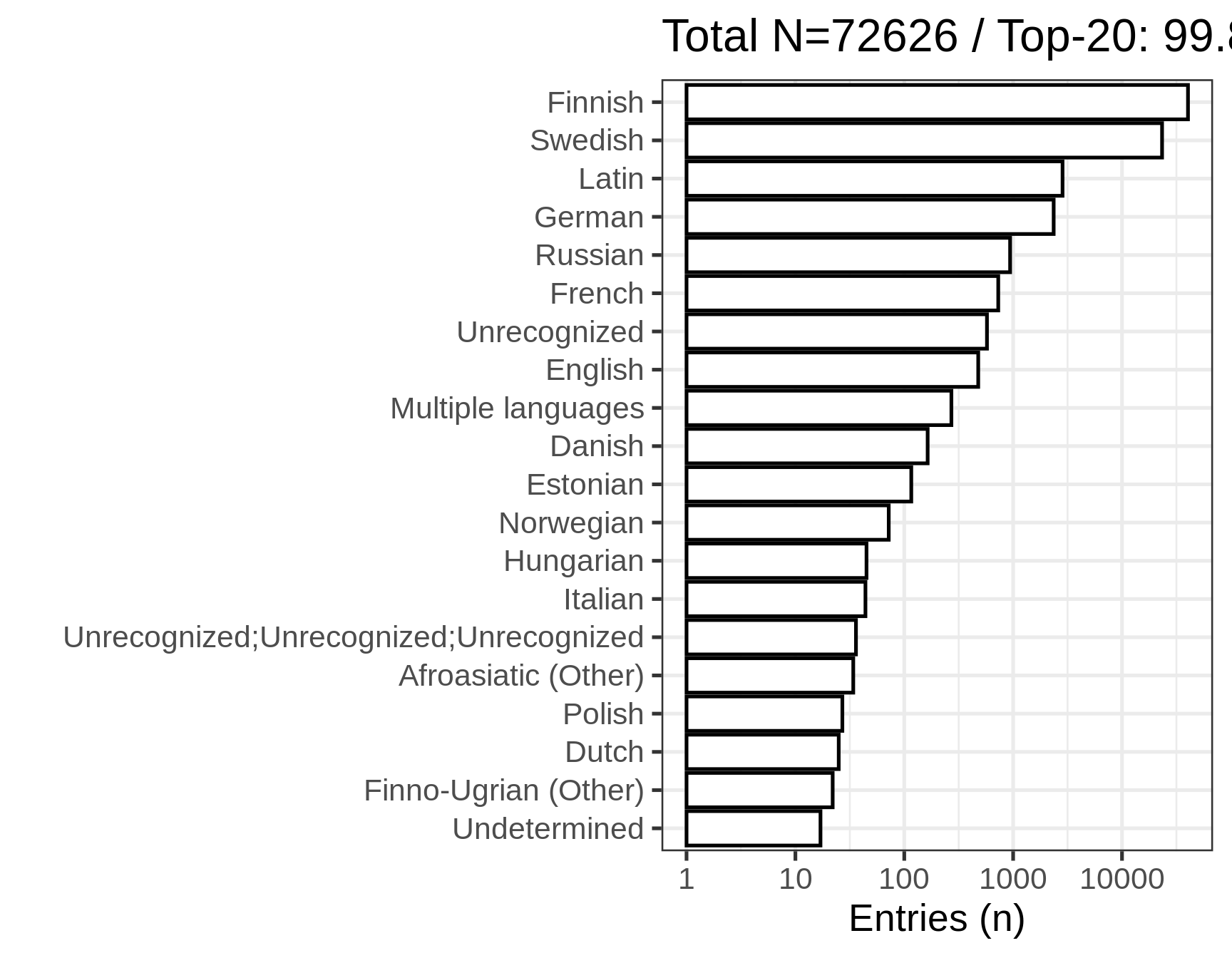
Number of titles assigned with each language (top-10). For a complete list, see accepted languages (1809-1917).
| Language | Entries (n) | Fraction (%) |
|---|---|---|
| Finnish | 40378 | 55.6 |
| Swedish | 23338 | 32.1 |
| Latin | 2844 | 3.9 |
| German | 2357 | 3.2 |
| Russian | 938 | 1.3 |
| French | 730 | 1 |
| Unrecognized | 575 | 0.8 |
| English | 478 | 0.7 |
| Multiple languages | 271 | 0.4 |
| Danish | 164 | 0.2 |
Title count per language (including multi-language documents; note the log10 scale):
7.4 Field 041,h: Original Language of Translations
MARC field 041 subfield h records the original language of a work when the bibliographic record describes a translation.
This field should be interpreted as translation-related metadata: records with a value in language_original are records for which Fennica contains information about the original language of the work. However, the absence of 041,h does not necessarily prove that the record is not a translation; it only means that no original-language information was recorded or extracted from this field.
7.4.1 Complete Dataset Overview
Unique original languages: 148
Unique primary original languages: 0
There are 196600 records with original-language information in 041$h, accounting for 14.92% of the complete dataset. These records can be treated as translation records with recorded original-language metadata.
There are 1121463 records without original-language information in 041\(h, accounting for 85.08% of the complete dataset. These records should not automatically be interpreted as non-translations; they only lack recorded 041\)h information.
194498 records have one original language recorded. This corresponds to 98.93% of records with 041$h information.
2102 records have multiple original languages recorded, accounting for 1.07% of records with 041$h information. This includes entries explicitly coded as “Multiple languages” as well as records where more than one original language is listed.
There are 0 records where the original language is marked as “Undetermined”, coded as “und”. This accounts for 0% of records with 041$h information.
Unrecognized original languages provides details of language values that were discarded during harmonization, in total: 77.
Additionally, the error list contains record IDs associated with discarded original-language values. These records are intended for librarian review.
Conversions from raw to preprocessed original-language entries
| Original language | Entries (n) | Fraction of records with 041$h (%) |
|---|---|---|
| eng | 91720 | 46.7 |
| swe | 25332 | 12.9 |
| fin | 20380 | 10.4 |
| ger | 13040 | 6.6 |
| fre | 9087 | 4.6 |
| und | 8439 | 4.3 |
| rus | 6052 | 3.1 |
| nor | 3972 | 2 |
| dan | 3573 | 1.8 |
| ita | 2568 | 1.3 |
7.4.2 Subset Analysis: 1809–1917
Unique original languages, 1809–1917: 43
Unique primary original languages, 1809–1917: 0
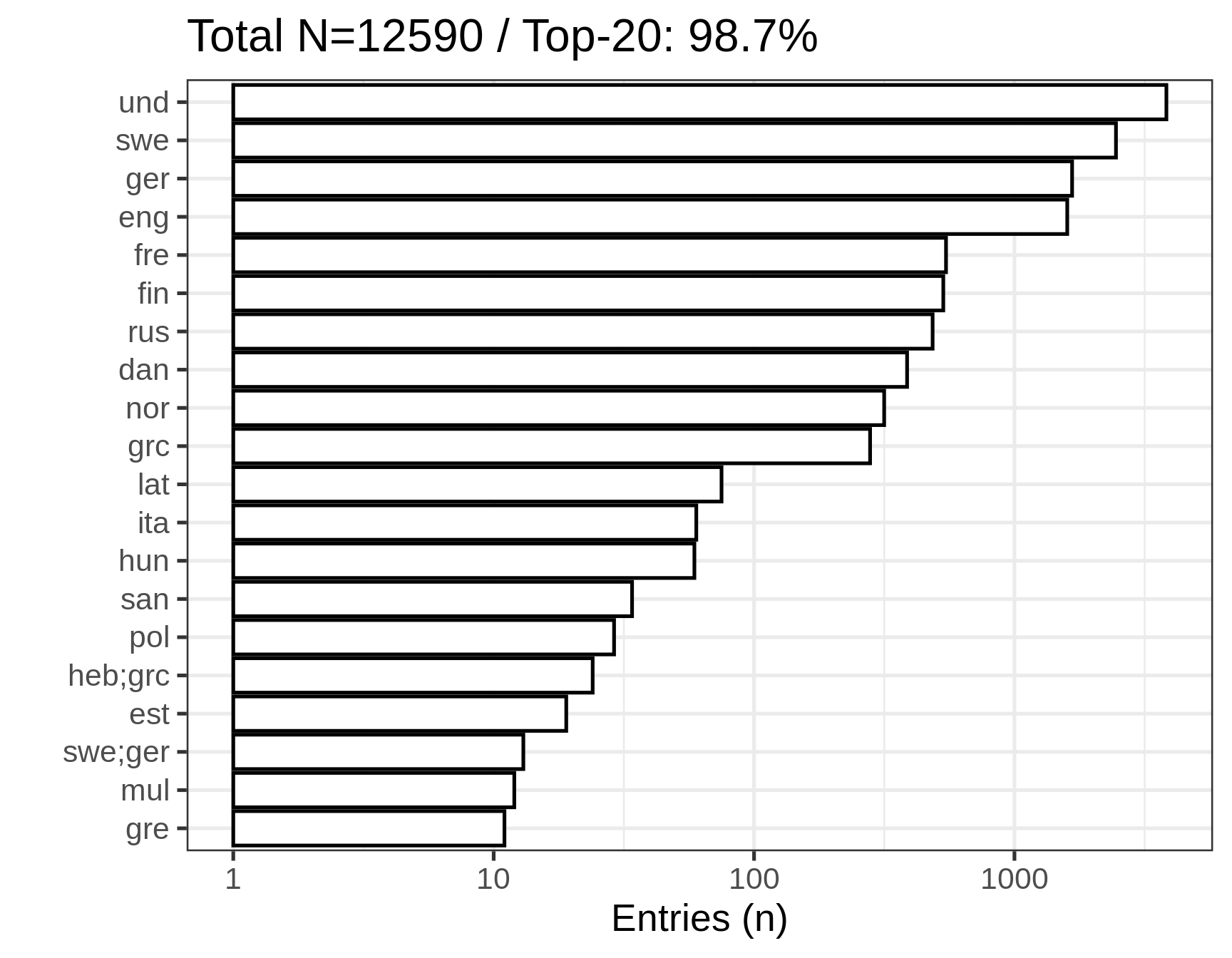
There are 12590 records with original-language information in 041$h in the 1809–1917 subset, accounting for 17.34% of the subset.
There are 60036 records without original-language information in 041$h, accounting for 82.66% of the 1809–1917 subset.
12473 records have one original language recorded. This corresponds to 99.07% of records with 041$h information in the 1809–1917 subset.
117 records have multiple original languages recorded, accounting for 0.93% of records with 041$h information.
There are 0 records where the original language is marked as “Undetermined”.
7.4.3 Top Original Languages for 1809–1917
The following table shows the most common original languages recorded in 041$h for the 1809–1917 subset. Counts include records with multiple original languages. For a complete list, see accepted original languages, 1809–1917.
| Original language | Entries (n) | Fraction of records with 041$h (%) |
|---|---|---|
| und | 3833 | 30.4 |
| swe | 2454 | 19.5 |
| ger | 1665 | 13.2 |
| eng | 1595 | 12.7 |
| fre | 546 | 4.3 |
| fin | 533 | 4.2 |
| rus | 485 | 3.9 |
| dan | 387 | 3.1 |
| nor | 316 | 2.5 |
| grc | 279 | 2.2 |
Title count per original language, including records with multiple original languages. Note the log10 scale: