3 Author’s info: name
3.1 Author name for Language material (books) in 100,a - field.
Author’s name section’s summary tables offer insights into the dataset’s integrity, illustrating the accepted and discarded author names. An examination of missing values in the original dataset provides transparency regarding data completeness. The inclusion of information on name variants and pseudonyms enriches the analysis, addressing nuances in authorship representation. This comprehensive approach ensures a thorough understanding of the dataset’s composition and the intricacies associated with author identification.
3.1.1 Complete Dataset Overview for 100 field
- Unique accepted entries in original data: 209942
- Unique discarded entries in original data (excluding NA cases): 9
- Original documents with non-NA titles 835654 / 1318063 (63.4%)
- Original documents with missing (NA) titles 482409 / 1318063 documents (36.6%)
3.1.3 Complete Dataset Overview for 700 field
- Unique accepted entries in original data: 193893
- Original documents with non-NA titles 393139 / 393139 (100%)
- Original documents with missing (NA) titles 0 / 393139 documents (0%)
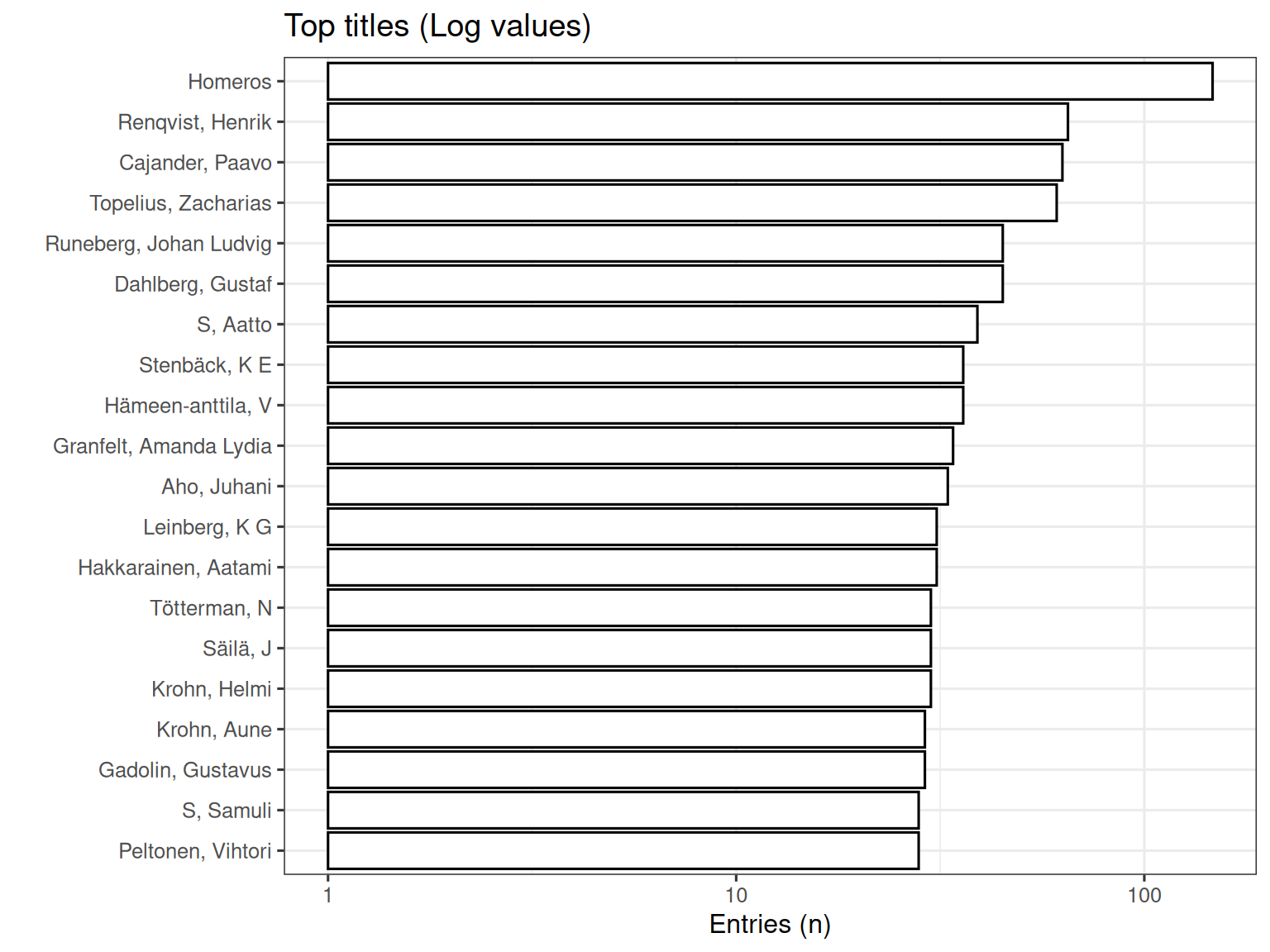
3.1.4 Author’s name (700a) - Top 20
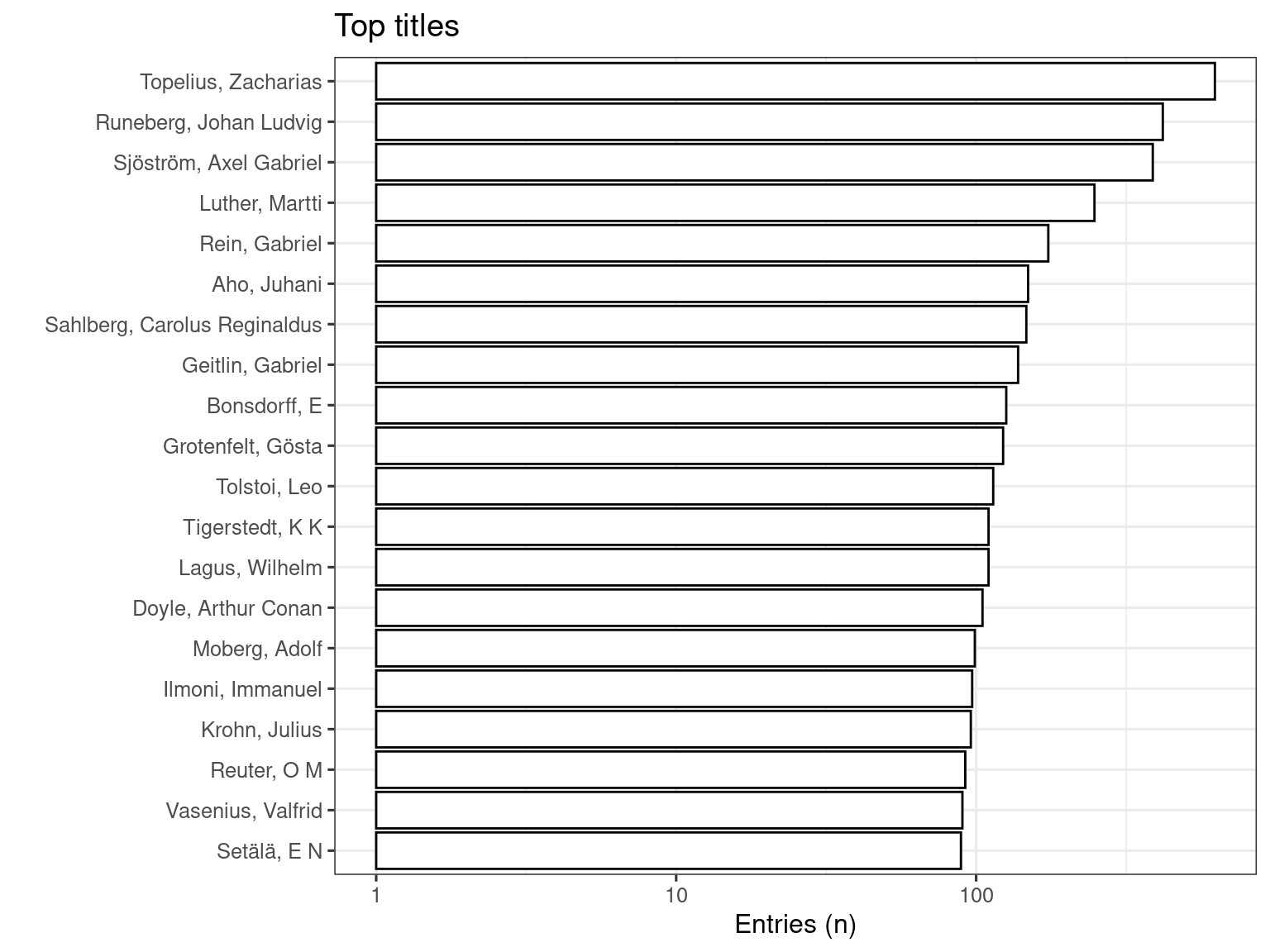
3.1.5 Subset Analysis: 1809-1917 100,a
Top-20 titles and their title counts for period 1809-1917.
The accompanying plot visually underscores the prominence of these authors, emphasizing the metric of the number of unique titles published by each author.
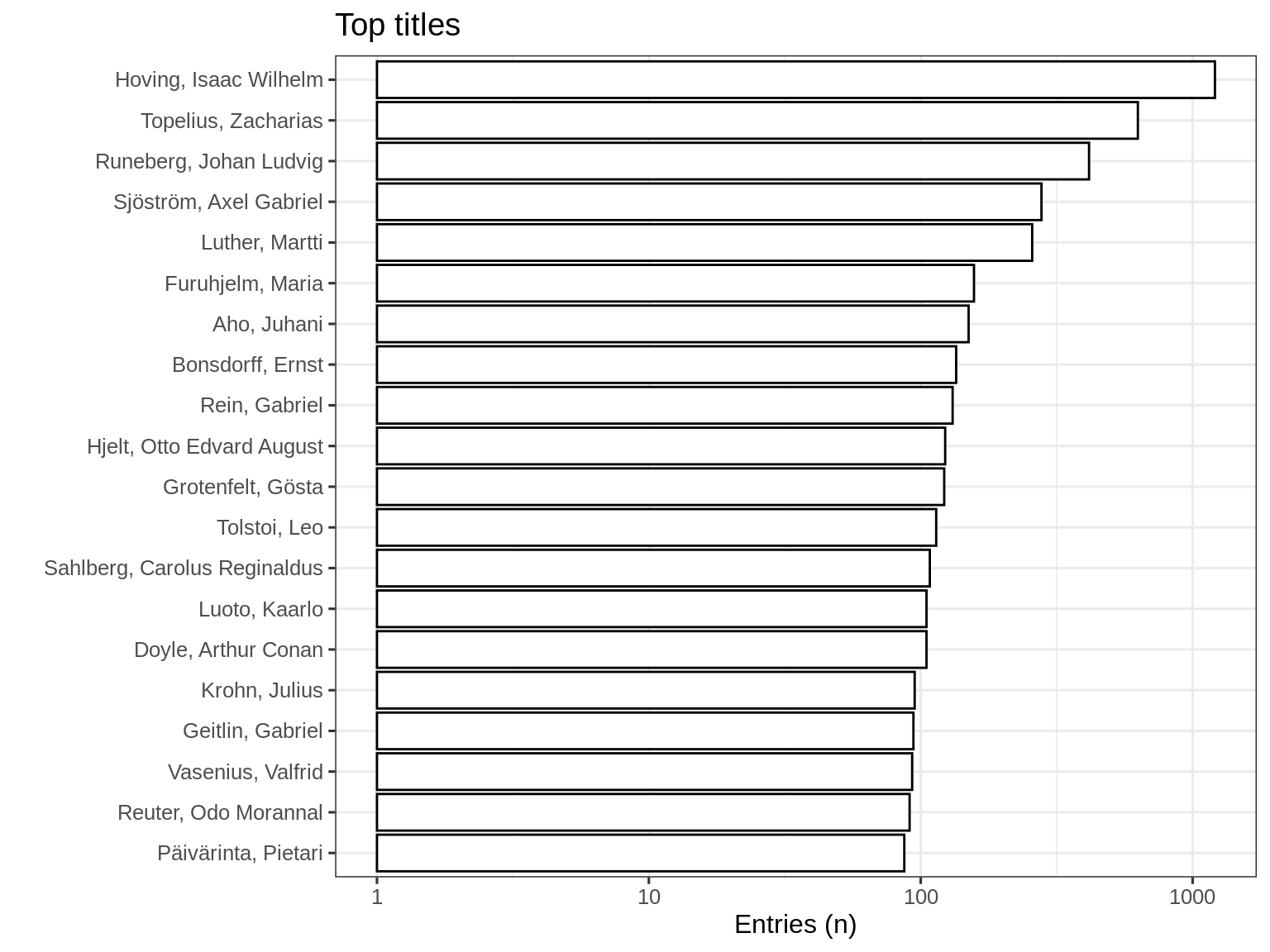
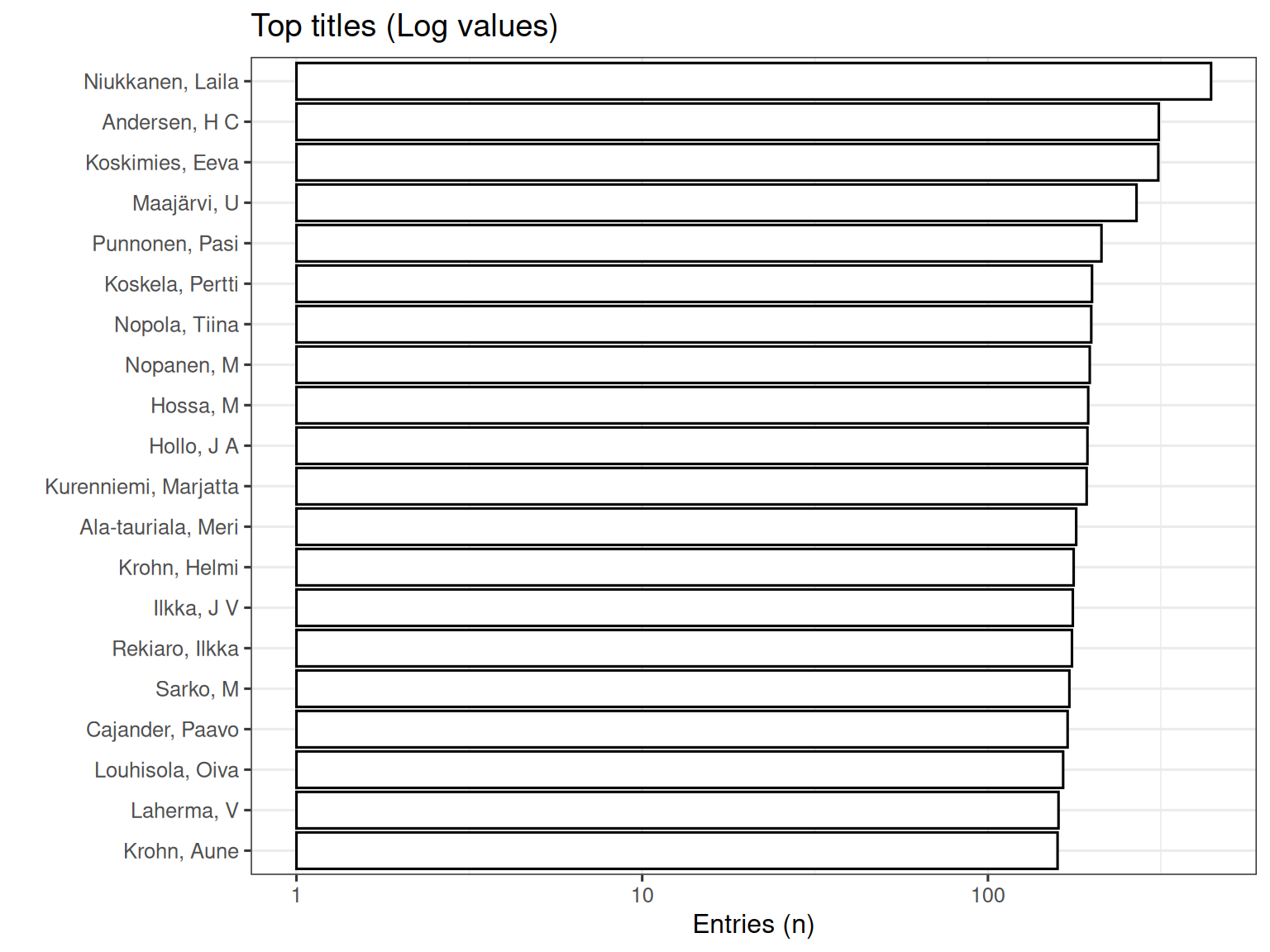
3.1.6 Subset Analysis: 1809-1917 700,a
Top-20 titles and their title counts for period 1809-1917.
The accompanying plot visually underscores the prominence of these authors, emphasizing the metric of the number of unique titles published by each author.